AI Dreaming: Self-Play Sleep Cycles for Adaptive LLM Agents
Reece Robinson, CTO, Orchestral
Abstract
Let Them Sleep proposed that specialised LLM-based agents can improve by capturing structured episodic memories during the “day” and refining a lightweight overlay model (e.g., adapters/LoRA) during “sleep”. This follow-up extends that premise with AI Dreaming: during sleep, an agent uses curated real memories to generate plausible adjacent scenarios and runs self-play rollouts through those scenarios. The intent is to mimic a rehearsal process — playing out nearby possibilities from limited experience — so the agent can generalise from sparse data, become more robust to operational variance (ambiguity, partial data, tool errors), and learn repair behaviours. I outline a practical architecture for grounded dreaming, propose a scoring and distillation approach compatible with overlay refinement, and show how healthcare-grade evaluation rubrics can be used to make the critic reliable and clinically aligned.
AI Dreaming is a form of self-play training for LLM agents, combining synthetic data generation, scenario simulation, and critic-based evaluation.
1. Motivation
In production, agents rarely fail only on the “main path” of common interactions. They fail in the surrounding neighbourhood: a request phrased differently, missing context that should have triggered a clarifying question, partial tool results, conflicting evidence, or transient tool errors. Collecting enough real interactions to cover this neighbourhood is slow and expensive — and feedback is often delayed or noisy in healthcare settings.
Humans appear to bridge this gap by simulating variations of recent experiences. I replay an event, imagine alternative responses, and explore “what if” branches that never occurred. AI Dreaming formalises that leverage: use a small set of trusted, real episodes to cheaply explore a much larger set of adjacent experiences, then distil what was learned into the agent’s overlay model and policies.
The practical promise is threefold: - Generalisation from sparse data: one real episode can seed many nearby learning opportunities.
Robustness to variance: tool flakiness and partial data become part of training, not surprises.
Repair learning: the agent learns how to recover when it makes mistakes, not only how to behave when everything goes right.
1.1 Applicability
AI Dreaming is most useful when agents operate in environments with (1) long-horizon workflows, (2) tool dependence, and (3) high consequence failure modes. In these settings, real experience is often sparse and skewed toward common paths, while failures cluster in adjacent edge cases: ambiguity requiring clarification, partial or conflicting tool outputs, and transient operational errors. Healthcare-adjacent agents are a natural fit because correctness and safety depend as much on process (appropriate verification, escalation, and uncertainty calibration) as on final answers. Dreaming provides a mechanism to systematically rehearse these rare-but-important variations, then distill repair behaviours into the overlay model under conservative regression gating.
2. Core Idea
AI Dreaming is a sleep-time self-play loop driven by an agent’s episodic memory. Each episode — capturing user intent, intermediate artifacts, tool calls, tool outputs, and outcomes — becomes a “seed” for generating a neighbourhood of related scenarios. The agent then practices those scenarios in a controlled environment, receives critique and scores, and the best trajectories are distilled into training data for an overlay update.
The key is plausibility with constraints. Dreams should not be unconstrained imagination; they should be adjacent to real experience and compatible with the agent’s real operating environment (tool contracts, domain invariants, policy rules). This is what makes the generated experiences useful rather than destabilising.
Typical scenario families include: - Intent variations: plausible alternative goals and constraints for the same user/context.
Ambiguity forks: multiple interpretations of the same request (forcing clarification policy).
Counterfactual tool outcomes: different but valid results, conflicting evidence, boundary values.
Failure injections: timeouts, partial responses, rate limits, stale caches, transient errors.
Edge-case perturbations: rare workflows, unusual but valid input formats, near-miss failures.
AI Dreaming is not a claim that self-play or synthetic training is new. Rather, the novelty is in how these ideas are operationalised for specialised, tool-using agents that must remain anchored to real-world constraints. The “dreaming” phase is explicitly grounded (generated under tool contracts and domain invariants), risk-aware (scored against safety- and trust-aligned rubrics), and deployment-safe (distilled into a lightweight overlay that is gated by regression tests and rollback). In this framing, dreaming is not free-form imagination; it is constrained rehearsal around real episodes, designed to improve robustness without destabilising production behaviour.
3. Sleep-Time Architecture
AI Dreaming fits as a modular extension inside the sleep pipeline from Let Them Sleep. The “dreaming” stage sits between curation and overlay refinement, producing high-quality synthetic practice traces that are grounded, scored, and gated.
This separation makes the system operationally safe: dreaming can be exploratory, while refinement remains conservative and gated by real-world regressions.
During the day, the agent performs tasks and logs structured episodic memories (intent, tool calls, outputs, outcomes). At night, curated episodes seed grounded “dream” scenarios that are explored via self-play rollouts. Trajectories are scored with a healthcare-aligned rubric and hard invariant checks, distilled (prioritising repair examples), and used to refine a lightweight overlay model. Deployment is gated by regression tests and rollback to prevent drift. See Figure 1.
4. Grounded Dream Generation
Synthetic data is only helpful if it trains behaviours that transfer. The biggest risk is “invented reality”: scenarios that violate tool contracts, domain rules, or plausible clinical constraints, which can teach brittle patterns. AI Dreaming mitigates this by generating dreams in two passes: first define what is allowed, then fill in what is said.
4.1 Constraint-first skeleton
Start each dream by constructing a structured scenario specification:
Allowed actions and tool schemas (inputs/outputs, required fields, error modes).
Domain invariants (schema validity, permission boundaries, workflow constraints).
Success criteria (what a correct completion looks like) and failure criteria (what to avoid).
Budget and termination rules (max tool calls, max turns, retry behaviour).
4.2 Natural-language fill-in
Only after constraints are set, generate the interaction surface:
Realistic user phrasing variants (including partial info and mild noise).
Context details consistent with the skeleton (no new facts that break invariants).
Optional adversarial-but-realistic patterns (prompt injection attempts, irrelevant demands).
Grounded tool outcomes are strongly preferred. Where possible, tool outputs should come from a tool harness (real tools in a sandbox, or constrained simulators calibrated from production traces) rather than free-form generation.
5. Self-Play Rollouts, Scoring, and Clinical Rubrics
Once a dream scenario is defined, the agent runs a rollout (i.e., one run/trajectory through a scenario): it makes decisions, calls tools, handles errors, and produces final outputs. A critic then evaluates both the trajectory (how the agent behaved) and the outcome (what it produced). This matters in healthcare because many “good sounding” answers can still be unsafe: missing red-flag escalation, overconfident tone, or failure to reconcile contradictions.
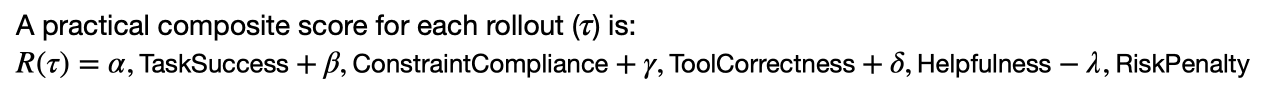
In a health setting, the critic is strongest when it is anchored to healthcare-oriented rubrics, not generic helpfulness. In practice, this means two things:
Rubric structure: use clinically meaningful headings (e.g., information quality, reasoning, communication/persona, safety/harm, trust/confidence), so “what good looks like” is aligned to clinical expectations.
Rubric content: instantiate these headings as many small, objective criteria that can be checked and weighted — especially safety-critical criteria (e.g., escalation, contraindications, uncertainty calibration).
This rubric anchoring also reduces reward hacking: criteria are explicit, granular, and auditable.
6. Distillation: Learning Repair, Not Just Perfection
A common failure of synthetic training is that it overproduces “ideal” examples and under-trains the messy reality of mistakes and recovery. AI Dreaming explicitly targets repair learning: the ability to notice and correct errors mid-flight, which is crucial for long-horizon tool-using agents.
Instead of distilling only “best final answers”, prioritise examples shaped like:
(state, attempted action, critique, corrected action)
(tool error, recovery plan, corrected tool call)
(ambiguous user request, clarifying question, subsequent plan)
Finally, synthetic traces must not dominate. Real episodes remain the anchor distribution; dream traces are capped and sampled for diversity and novelty.
7. Safeguards and Regression Gates
AI Dreaming introduces predictable risks: self-confirmation (the agent “practices” its own mistakes), drift (synthetic patterns pull behaviour away from reality), and reward hacking (optimising for the scorer). A safe implementation treats dreaming as exploratory and refinement as conservative.
Key safeguards: - Independent or ensemble critics to reduce self-affirmation loops.
Invariant-first validation: reject dreams and rollouts that violate schemas or domain rules.
Telemetry-informed priors: bias scenario generation toward what occurs in production.
Privacy scrubbing before sleep; dream from abstracted memory representations, not raw text.
Regression gate: overlays must not degrade on held-out real episodes, safety suites, and tool-contract tests; rollback automatically on regressions.
In clinical-document workflows, it can also be useful to adopt an explicit error taxonomy + harm framework so regressions are measured not just by “wrongness” but by potential clinical impact.
8. Evaluation
AI Dreaming should be evaluated on both offline and online metrics that reflect its purpose: robustness, safety, and recovery.
Useful measures: - Held-out real episode success rate, especially on historical failure clusters.
Tool-call validity rate (schema correctness, argument correctness).
Error recovery rate under injected tool failures (timeouts, partial responses).
Clarification quality: fewer unnecessary clarifications, more necessary ones caught.
Safety compliance: invariant adherence, leakage checks, policy compliance.
To keep evaluations clinically representative, it is helpful to map tasks to a healthcare task taxonomy (so coverage is explicit) and to standardise evaluation harnesses across use cases.
9. Limitations and Future Work
AI Dreaming depends on two foundations: (1) a critic reliable enough to rank rollouts, and (2) grounding mechanisms that prevent synthetic drift. Where tool behaviour is complex, building a faithful harness can be non-trivial. Future directions include learning calibrated simulators from tool traces, better uncertainty estimates to drive scenario selection, and more formal invariant checking to reduce reliance on subjective judging.
10. Conclusion
AI Dreaming extends sleep-cycle refinement by adding a grounded self-play phase: use real episodic memories to spawn plausible adjacent scenarios, practise them during sleep, and distil repair-focused trajectories into an overlay model. With strong constraint grounding, healthcare-aligned rubrics, and regression gates, this provides a practical pathway to improved generalisation and robustness without requiring a proportional increase in real-world interaction volume.
Appendix A: Representative Healthcare Rubric Sources for the Critic
This appendix lists examples of healthcare-oriented rubric and evaluation frameworks that can be used to structure the sleep-time critic. The intent is not to prescribe a single rubric, but to show how to anchor AI Dreaming’s scoring in established clinical evaluation practice.
1. Physician-authored, conversation-specific rubrics
Pattern: each conversation is graded against a set of clinician-written criteria with weighted points; criteria include both “must include” and “must avoid” items. Useful for: patient-facing communication agents, triage-style guidance, and clinician support that must meet explicit safety requirements. https://openai.com/index/healthbench/
2. Principle-based human evaluation frameworks
Pattern: top-level rubric headings covering information quality, reasoning, communication/persona, safety/harm, and trust/confidence; suitable as the “spine” of your critic rubric, with local criteria added per task type. https://pmc.ncbi.nlm.nih.gov/articles/PMC11437138/
3. Healthcare task taxonomies and evaluation harnesses
Pattern: define and map the agent’s tasks to a taxonomy so evaluation coverage is explicit and reproducible; useful for ensuring dreaming doesn’t overfit a narrow slice of use cases. https://crfm.stanford.edu/helm/medhelm/latest/
4. Clinical safety / hallucination assessment frameworks for clinical text
Pattern: error taxonomies and clinical harm frameworks for evaluating errors in generated clinical documentation; useful for weighting the RiskPenalty term by likely clinical impact and for building regression suites. https://www.nature.com/articles/s41746-025-01670-7
5. Granular “targeted rubric questions” approaches
Pattern: break complex evaluation into many small boolean checks to identify gaps efficiently; useful for turning clinician expectations into criteria that are easier to score automatically. https://research.google/blog/a-scalable-framework-for-evaluating-health-language-models/